Can Twitter Data Tell Us How A Movie Will Perform Next Week?
All day every day people are shouting to the world about every aspect of their life. They share on Twitter what they had for breakfast, what they just bought at the mall, how much they hate Mondays, and what their weekend plans are. If we gather all of this publicly shared information, can we predict how many people are going to go see a given movie next week?
By streaming tweets relevant to a movie of our choice straight from twitter we can get an idea for how many people are talking about the movie and what they're saying. By monitoring total twitter engagement and the overall sentiment about the movie we can predict movie performance as the following graph shows.
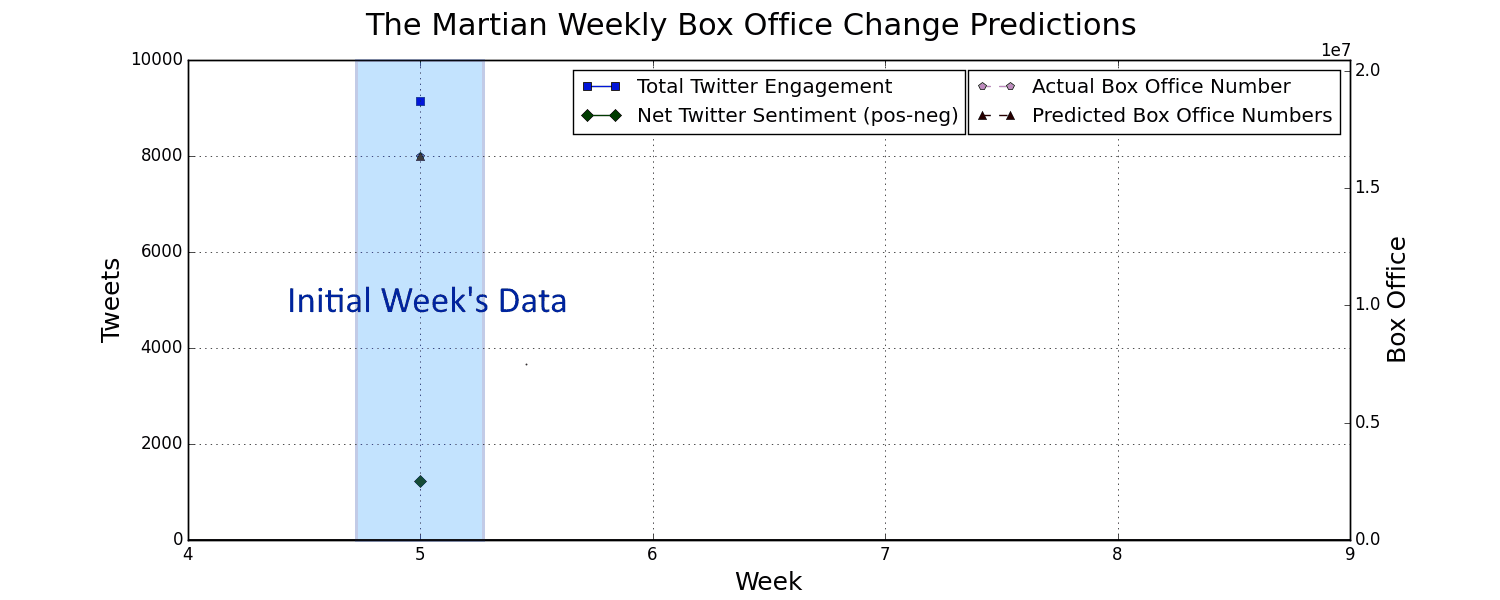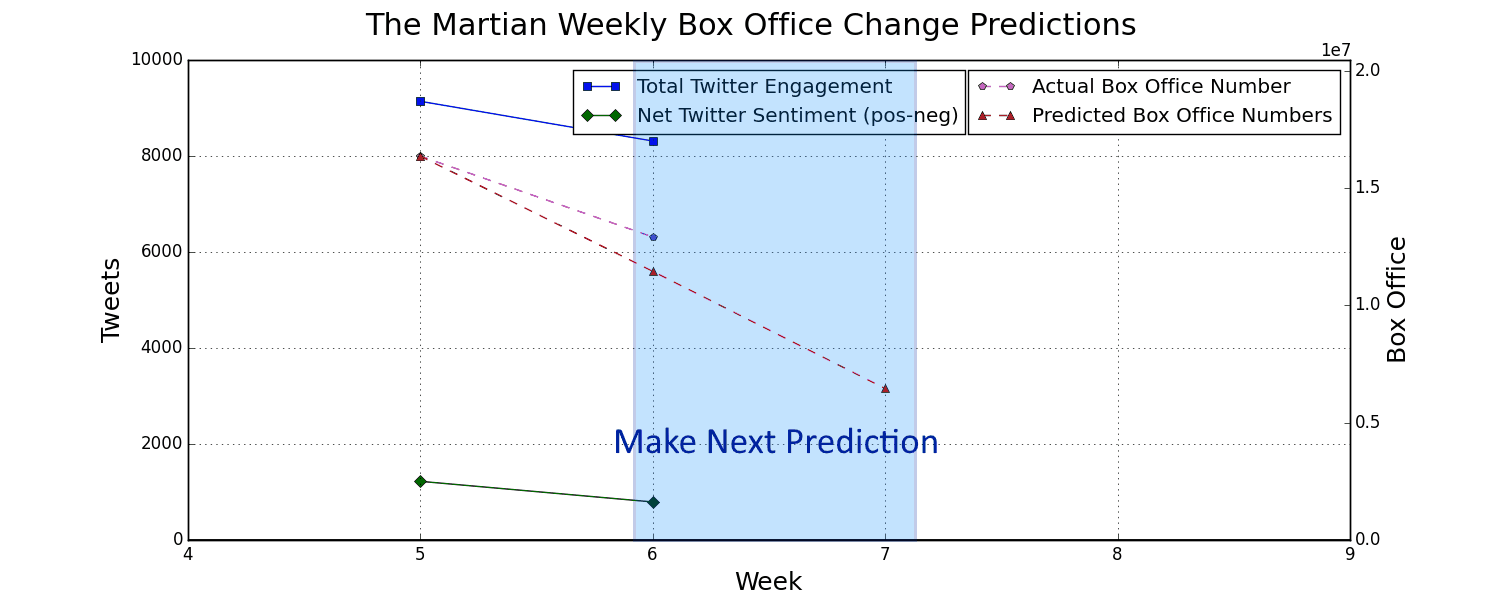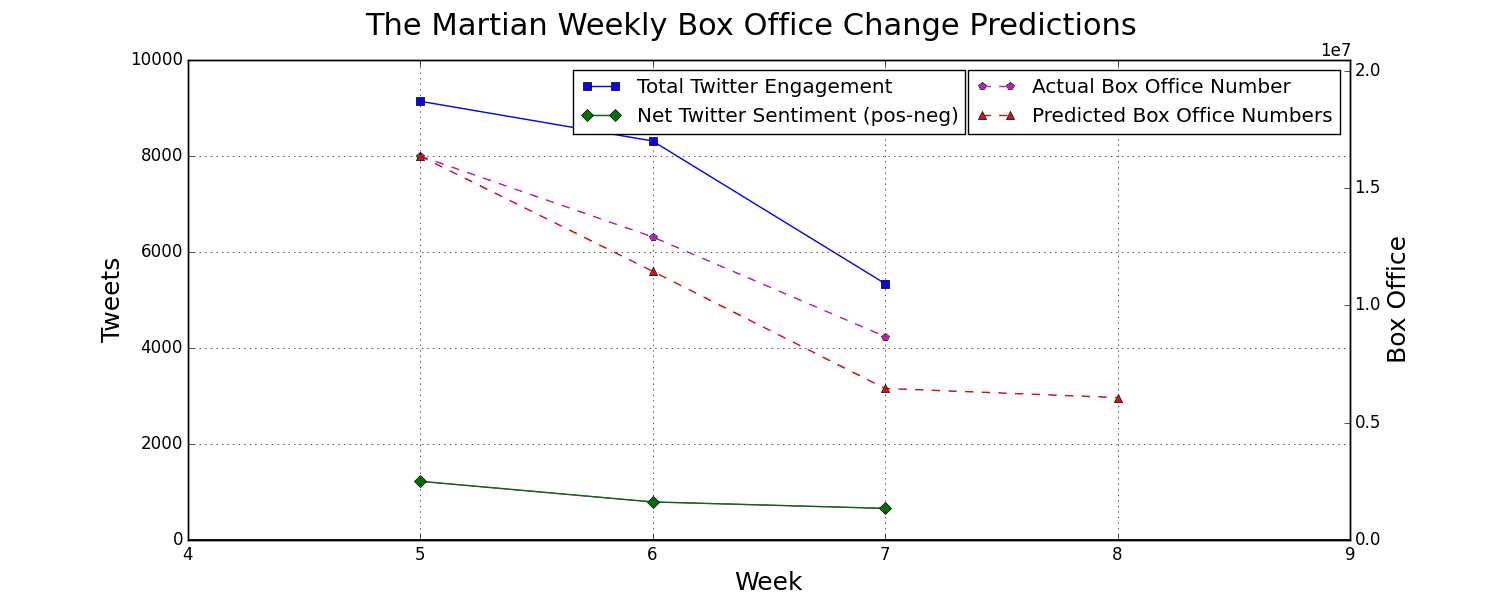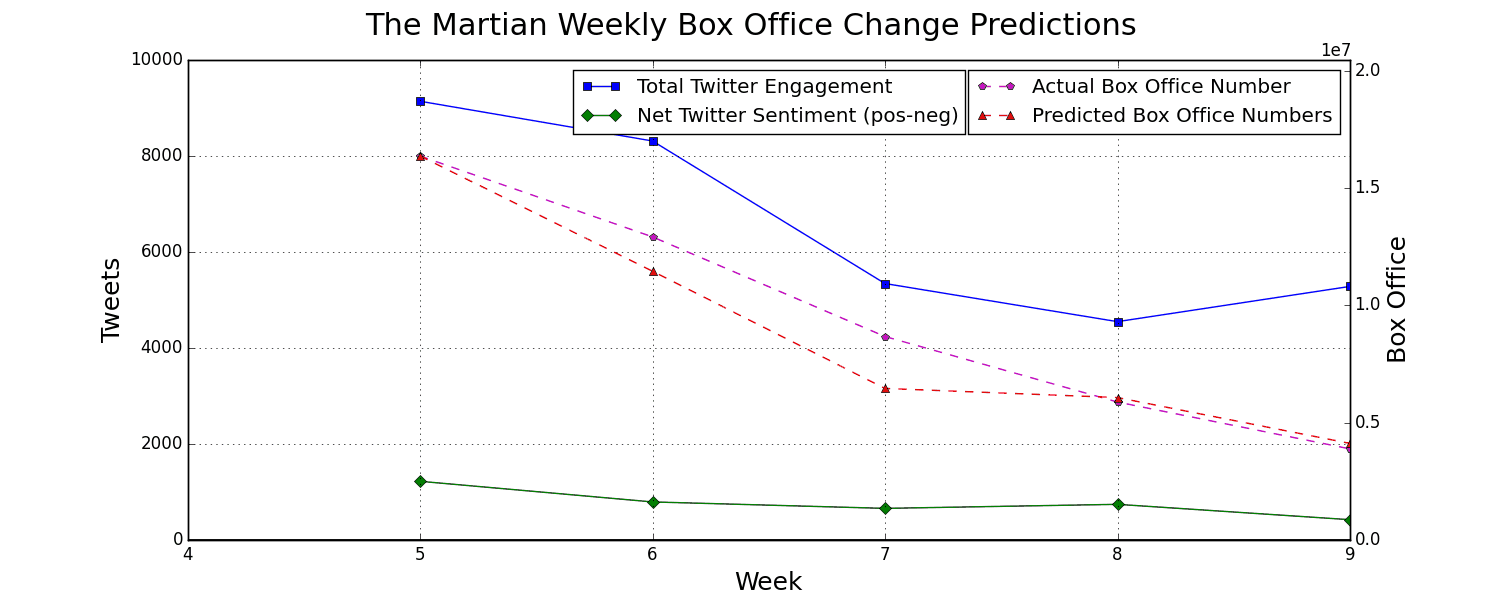
Why Would We Want To Predict Next Week's Movie Performance?
When a studio releases a movie, they don't just put it out there and hope people happen to go see it. They are actively engaged trying to convince the public to go show a movie through various forms of marketing. By tracking twitter engagement and predicting how well a movie will fare over the coming week gives insight into how well people are being reached and how effective current marketing campaigns are. This insight could help marketing teams to modify their campaigns to target a different demographic, reach people through a different form of media, etc. Most importantly, trying to predict the future is a really cool use of computer science.
Exactly What Kind of Information Is Tracked?
There are just two items tracked, tweets about a given movie, and how well that movie has been doing in the box office. There is, however, a lot of meaningful information that we can gather from just that data. First off, we can see how many people are talking about movie X in comparison to movie Y. We can also see how frequently people are talking positively about a movie versus negatively about it and also compare that to other movies. We refer to this as the sentiment. The difference between how many tweets are positive and how many are negative tells us the majority sentiment, which we refer to as the net sentiment. One of the most important factors we can gather is how do these things change from week to week. We can understand if people are still talking a lot about a movie after week 3 or 4, or if people really aren't talking about it as much anymore.
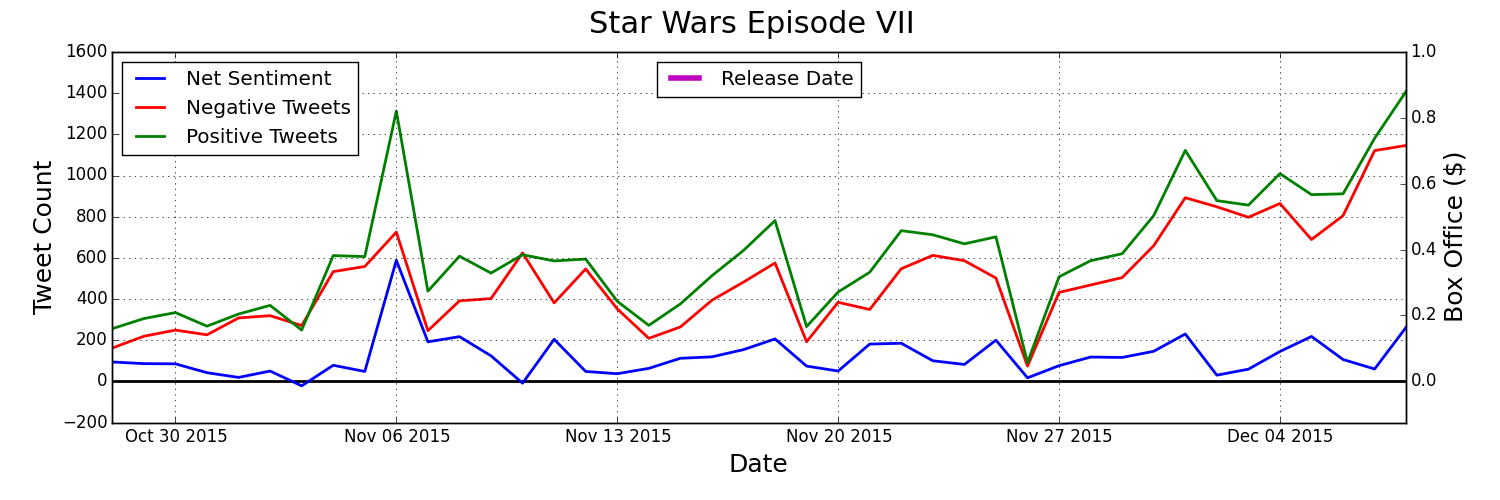
Here are some visualizations of that twitter and box office data being tracked for some recent movies:
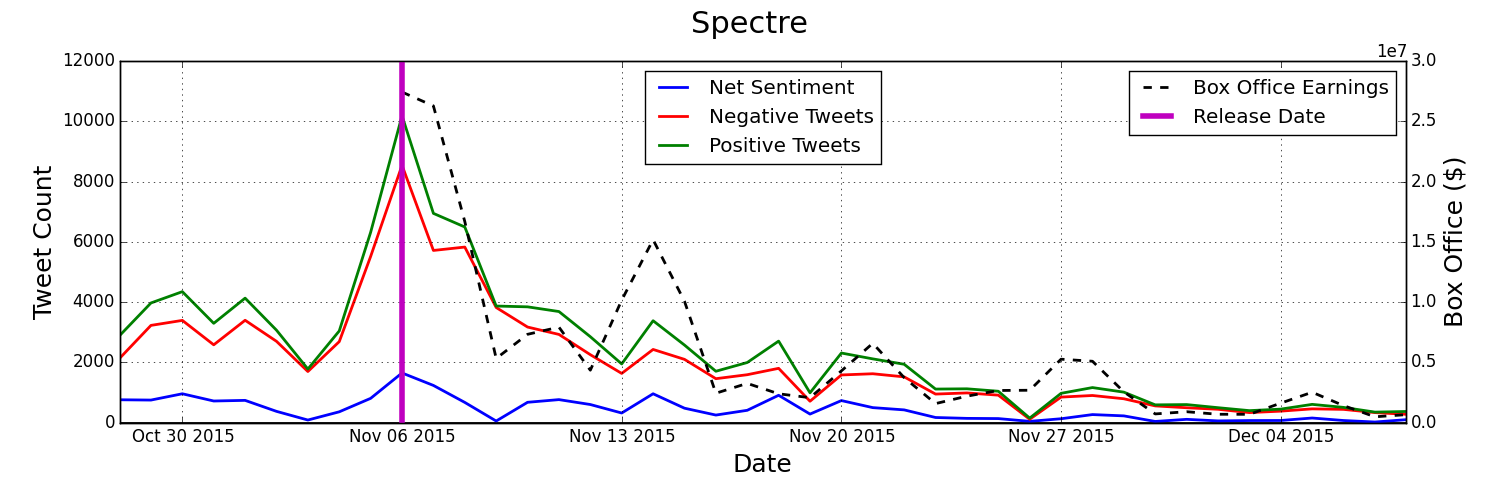
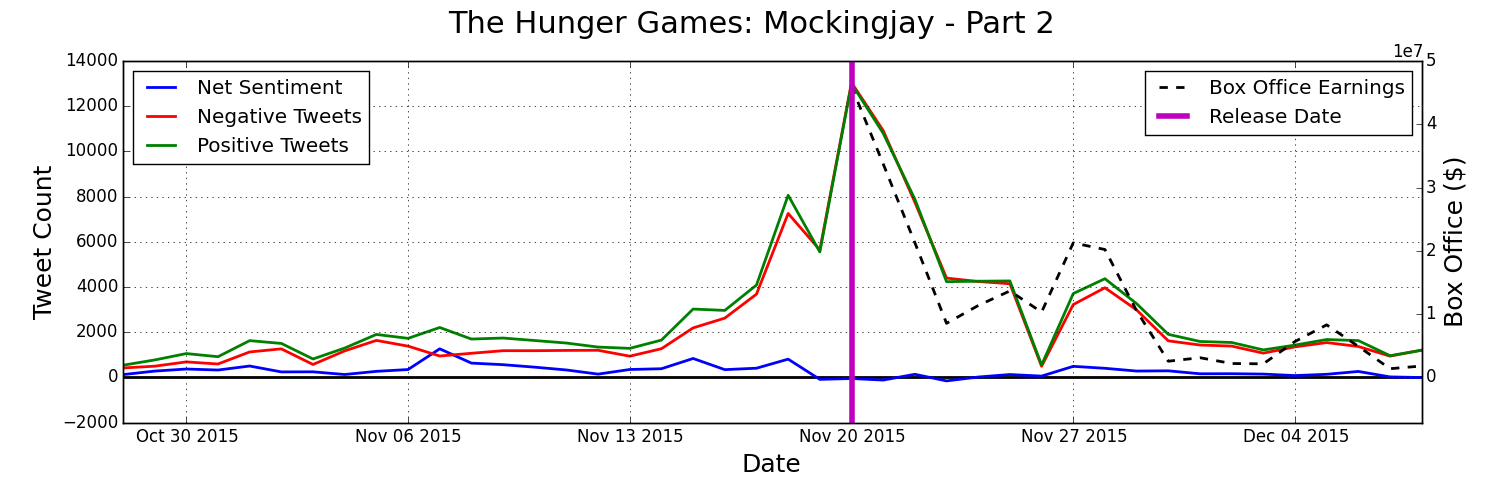
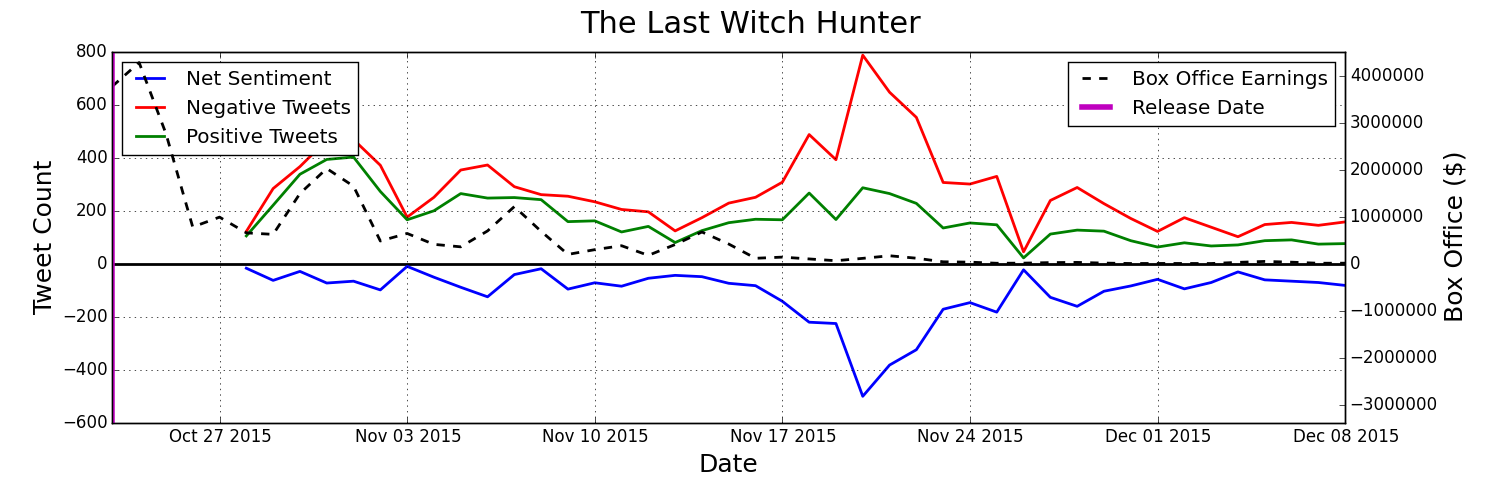
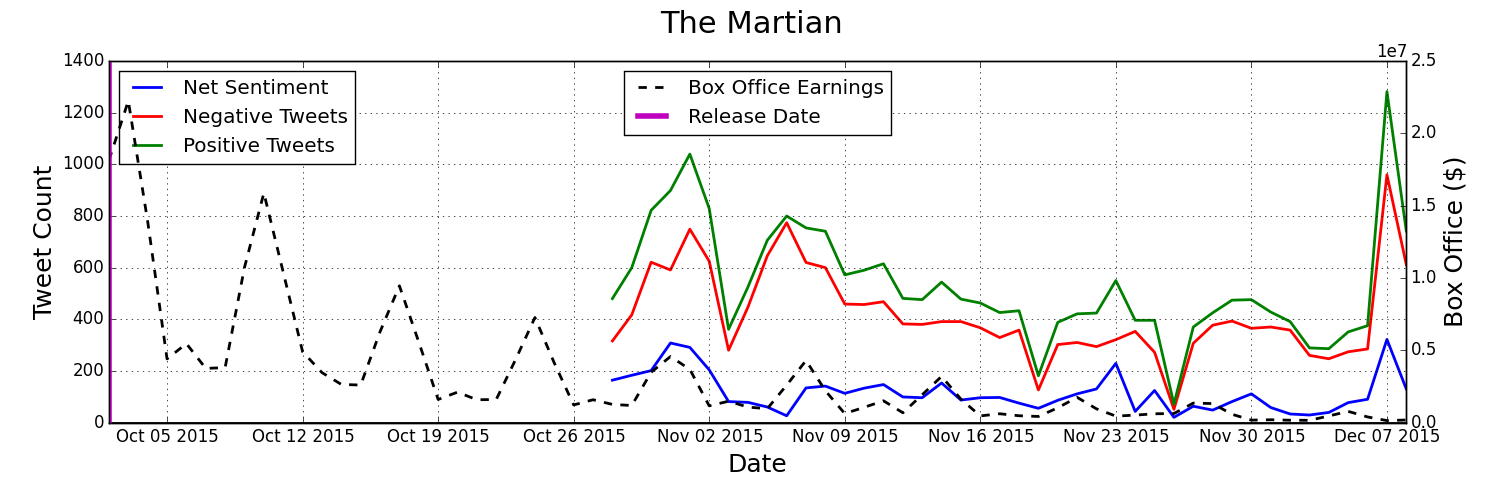
How Is The Data Gathered And Analyzed?
The first step is to gather the data from Twitter. By giving Twitter a list of keywords we can receive a live stream of all tweets that match those keywords. Before our system can analyze the tweet, it needs to be modified so that we can focus in on the most important features of the tweet. The words are stemmed, punctuation is removed, and we only keep adverbs, adjectives, and verbs because they have been most valuable in determining sentiment.
This is demonstrated here:

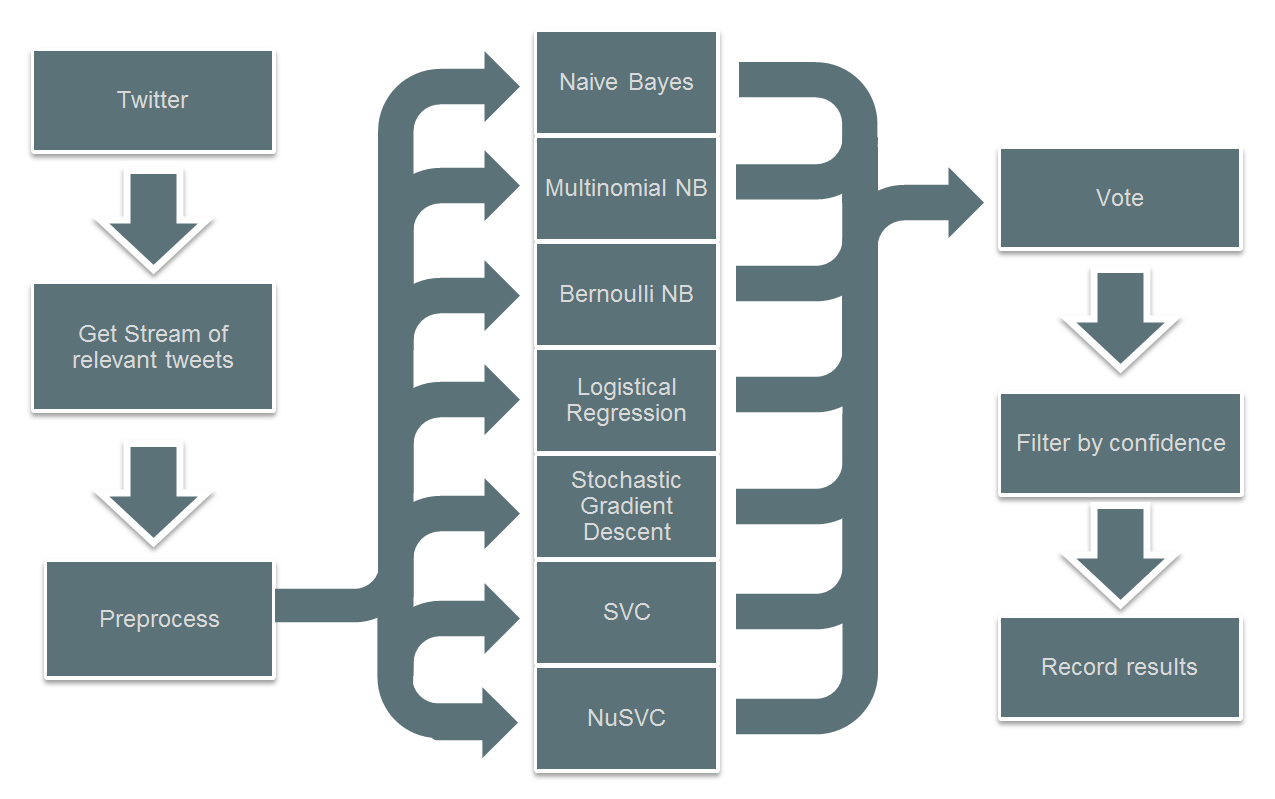
Now that the tweet is ready, it is passed on to a series of machine learning classification algorithms that will each analyze and tell us whether it believes that tweet is speaking positively or negatively. Due to the complexity of spoken languages, especially with words having multiple meanings, these classifiers are not perfectly accurate. In order to improve our results, we use several of them, and each one votes on what it thinks the correct answer is. We then take whichever answer is most popular as the correct answer. That result is then stored for later use.
A flow chart of this process can be seen here:
Gathering the other part of the data, the box office numbers, is much simpler. Thanks to sites like Box Office Mojo, the box office numbers are readily available. All we need to do is point our program at a webpage for each movie and read the box office data and store it.
How Are Predictions Made?
Because box office numbers tend to follow a weekly trend of being low at the beginning of the week and high on the weekends, we group all of our data into weeks to reduce the affect that has on our tests. Then for each week we calculate key features. The features we currently gather are: whether the total twitter engagement went up or down since last week, the percentage difference of engagement between the two weeks, the overall sentiment this week (positive, negative, or neutral), and how much did the sentiment change from last week to this week.
Those features for each week are passed through a classifier called a decision tree. The decision tree was built on the features of past weeks that we had gathered. The tree picks out patterns in the features and uses that to make a prediction. In this case our prediction comes in the form of the percentage change we should see from this week's box office numbers to the next week's numbers. Decision trees are limited on the number of results they can return, so in this case the percentage is a value rounded to the nearest 10%.
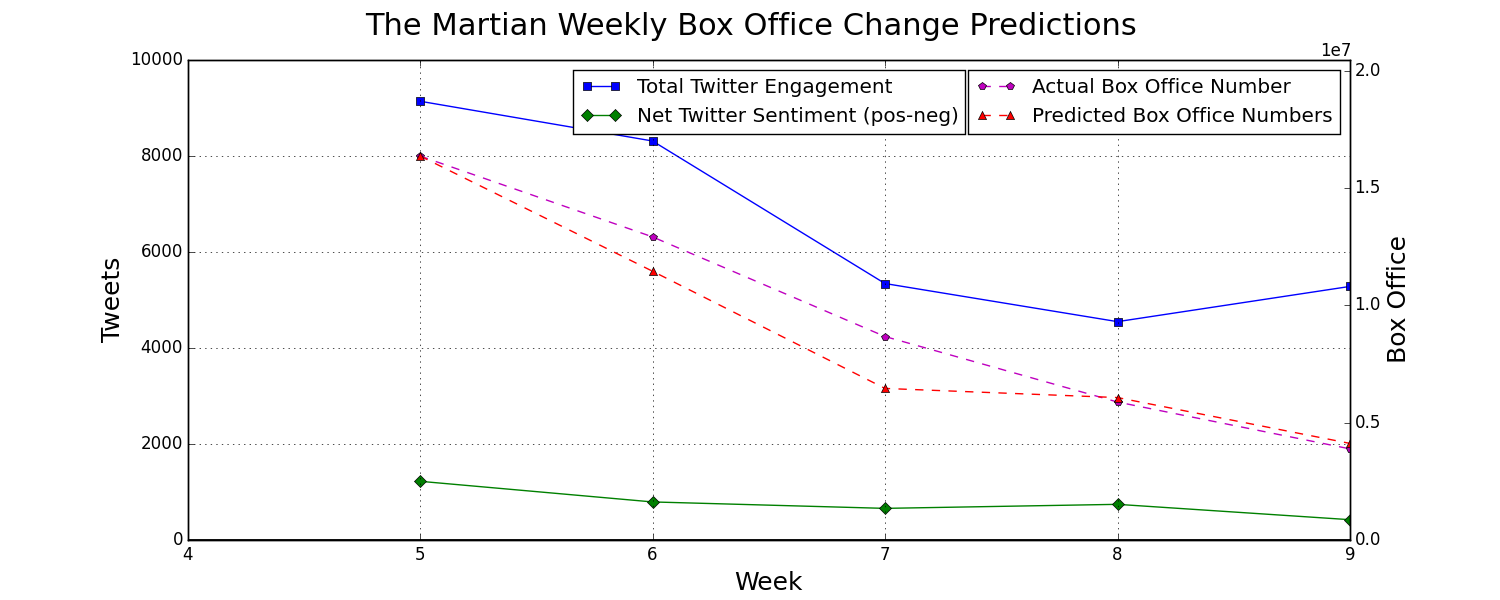
Here is another look at the predictions shown above. This is for a movie that the tree has never seen before and most weeks it is within 0-10% of the correct change. The data starts at week 5 because the movie had already been out for several weeks before we started gathering our Twitter data.
Limitations And Potential Future Work
The amount of data that was able to be collected before building the decision tree was fairly small. This is mostly due to the rate at which movies come out and the short time period (~6 weeks) that the data was able to be collected. Another challenge for this was the limitation Twitter has on how many tweets you can receive on a stream in a given period. If too many keywords are requested (to allow you to track more movies), too many tweets will match your search terms at a given moment and Twitter will just return a notification that the count was too high. There may be ways to get around this limitation and to allow us to track a higher number of movies at once.
This low amount of data made for a predictor that is semi-accurate for movies that follow the usual downward trend. For movies that don't fall very fast, or that actually increase week over week, the predictor won't have ever seen anything like that and will not be able to predict that.
Many movies have titles that are just words used in common speech. The current system has no effective way of determining if a tweet relates to the movie, or to something else involving that word. This leaves some movies unable to be followed or predicted with the current system.
Another area that could be improved on is the sentiment analysis. When dealing with tweets, there is often very little data to work with to make a prediction. The classifiers used in this project did fairly well and I was able to get them all to ~80% accuracy. If this can be further improved it will greatly help in having more accurate sentiment results.
Libraries And Resources Used
- This project was written in Python
- Python Natural Language Toolkit
- scikit-learn machine learning toolkit for Python
- Tweepy Twitter API library for Python
- Beautiful Soup HTML parser
- Python Programming Tutorials for NLTK